Join the Beta!
If you are interested in joining the beta version, check the website. Below is a brief explanation of the methods used to develop EyeRub. For more details, please check out the paper (under review). You can also watch here (in French) the presentation at SAFIR 2023, Paris.
Abstract
In this work, we present a new machine learning method based on the Transformer neural network to detect eye rubbing using a smartwatch. In ophthalmology, the accurate detection and prevention of eye-rubbing could reduce incidence and progression of ectasic disorders such as Keratoconus, and prevent blindness. Our approach leverages the state-of-the-art capabilities of the Transformer network, widely recognized for its success in the field of natural language processing (NLP). We evaluate our method against several baselines using a newly collected dataset and achieve an impressive accuracy of 97% with fine-tuning. Notably, our model operates in real-time on an Apple Watch, enabling prompt detection and response.
Problem Statement
The goal of the study is to create a tool using machine learning to identify eye rubbing from AppleWatch sensor data, aiming to investigate its link with corneal diseases like keratoconus. A key challenge is distinguishing between similar hand-face interactions. The proposed solution involves developing a machine learning model capable of classifying different hand-face activities, as depicted in the study's pipeline illustration.

Input
The AppleWatch provides sensor’s measures sampled at 50Hz. The signals are composed of the 19 following features provided by the sensors of the AppleWatch:
- Raw Accelerometers Data:
- Acceleration x,y,z in G’s
- Processed Device-Motion Data:
- Yaw, Roll, Pitch in rad.
- Rotation Rate x,y,z in rad/s.
- User Acceleration x,y,z in G’s
- Quaternion x,y,z,w
- Gravity x,y,z in G’s
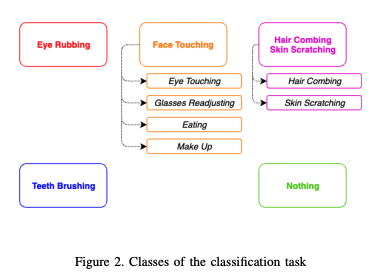
Output
The classes of the classification task are illustrated bellow:
Methods
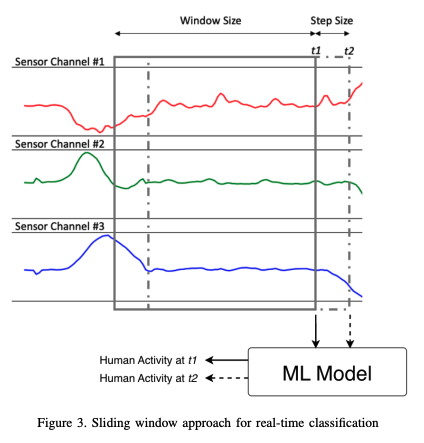
Real-time classification
To enable real-time operation on the Apple Watch, a sliding window method is employed, where the continuous sensor data stream is segmented into fixed-size windows of 3 seconds, with a step size of 0.5 seconds. Each window is analyzed by a machine learning model to extract features and classify human activities, enabling activity recognition every 0.5 seconds based on the preceding 3 seconds of sensor data.
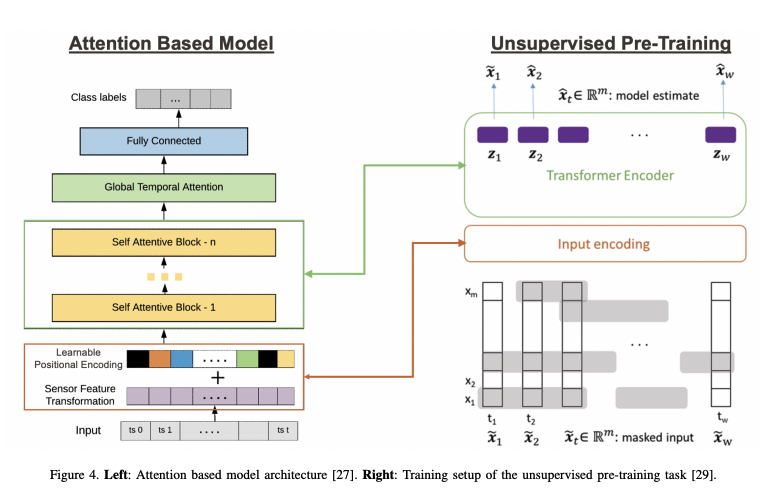
Model Architecture
The model employs an attention-based architecture, and its encoder is pre-trained through denoising unlabeled sequences.
Dataset
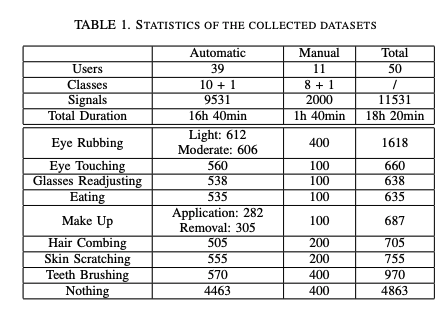
Table below summarizes the statistics of the collected datasets. The automatic labelling setup resulted in signals of variable length. For those signals, we provide statistics of the raw collected signals per user, presented as interactive plots, here.
Results
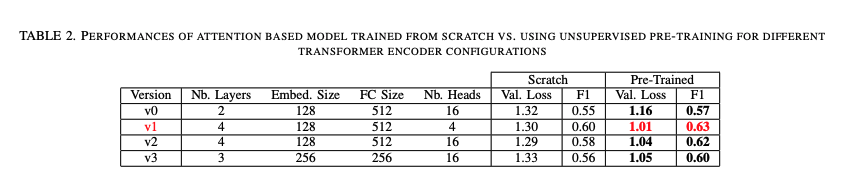
Effectiveness of unsupervised pre-training
Results below confirm that unsupervised pretraining offers a substantial performance benefit over fully supervised learning both in term of classification performance (F1-Score) and prediction confidence (cross entropy loss).
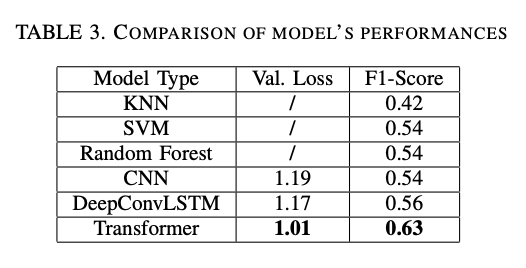
Performances Comparison
Based on the results presented below, we confirmed that the attention-based model (Transformer) outperforms both traditional machine learning and deep learning methods by a significant margin.